Voice Sweetening with Fairlight
DaVinci Resolve Quick Tips: Voice Sweetening with Fairlight
By Ross Papitto
Modern cameras are great. They’re super high resolution, super sharp, and super easy to get a filmic look even on a budget. Chances are you’ll want to do some post-production like color correction and VFX work so that your image emphasizes the story.
Modern microphones are great too. They’re super high-fidelity, super clear, and super easy to get a great sound even on a budget. Chances are you’ll want to do some post-production work like EQ and compression so that your sound emphasizes the story.
Chances are you’d like to do this all in the same program.
Enter DaVinci Resolve.
 You color-correct. You should sound-correct too. Credit Subtraction.com
You color-correct. You should sound-correct too. Credit Subtraction.com
DaVinci Resolve possesses a slew of audio plugins in their Digital Audio Workstation that can really sweeten up your dialog tracks and make your videos come to life. I don’t care if Roger Deakins lit your commercial and Tom Poole color graded it; If it sounds like garbage, I don’t want to watch it. 24 frames per second or 96 THOUSAND audio samples per second. Which is larger? Which is more important? I know what Hitchcock would say…

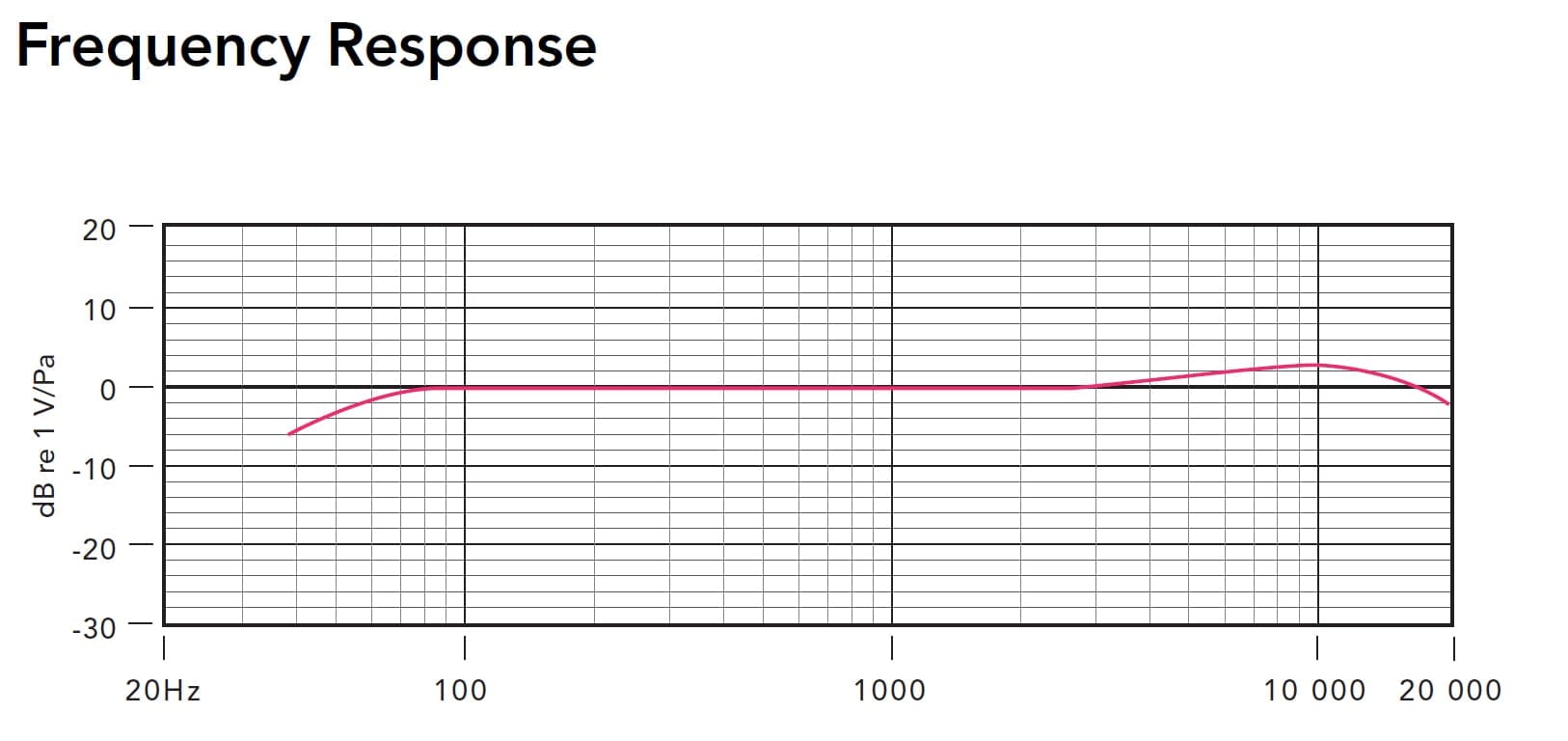
The frequency response of a rode NTG3 shotgun mic. Flat, and boring.
I’m sure you’ve been in a scenario where you’re editing log footage and the client asks you why it looks gray. “Where are all the colors?” Rather than bore them with details of image latitude and compression ratios you quickly switch on a LUT to shut them up and go about your business.
Modern microphones are similar in that they capture a flat response to sound, emphasizing neither the lows nor highs. They lack color, giving you lots of room to color them yourself to taste.
We’re going to sweeten our dialog tracks in three steps.
- EQ
- De-Ess
- Compress
In the video tutorial accompanying this article we actually had two microphone tracks to work with from our buddy Dale: a lav mic and a boom mic. I’d highly recommend using only one microphone for the finished video to avoid phase issues between the two mics. I know you’re probably a video guy/gal so I don’t want to put you to sleep with audio techtalk, but basically if the two mics are receiving sound at slightly different times, they might start to cancel each other out and sound thin and weak. Not ideal. I ended up only working with the lav mic here.
When EQing, well, anything, the general rule is that subtractive EQ is more effective than additive EQ. To that end, we’re going to scan through the frequencies in Dale’s voice, listening for harsh frequencies that stand out, and we’re going to cut them drastically. That way, we can turn his voice up, without also turning up those unpleasant frequencies as well.

Look at that! Built in EQ for every audio track.
First I’d recommend utilizing a low-pass on Band 1 for all the subharmonic garbage we can’t even hear. Anything below 50hz is fair game here, but I’ll go even higher when editing a higher pitched voice. That way when we start to compress the voice later, those super low frequencies won’t be brought up in the mix, making our dialog sound woofy and unclear.
Now the fun part. Grab Band 2, boost it as far up as it can go with the “Gain” knob, and give it a very narrow bandwidth, or “Q Factor.” Play your dialog track and slowly move the frequency up until you hear something start to ring out unpleasantly. A safe move is, if it hurts your ears, you’ve found it. I’ll cut these harsh frequencies anywhere from 2 to 10 db depending on how bad they are. These could originate from the human voice, or just weird reflections in the room the dialog was recorded in.

Boost those frequencies to find the ugly ones. Then cut ‘em. Also note the low-cut at 53hz.
Repeat this for the remaining bands 3, 4, and 5, scanning and cutting. Make sure you’ve selected a “bell curve” for the bandwidth shape. It’s the one that looks like two hands making an O shape.
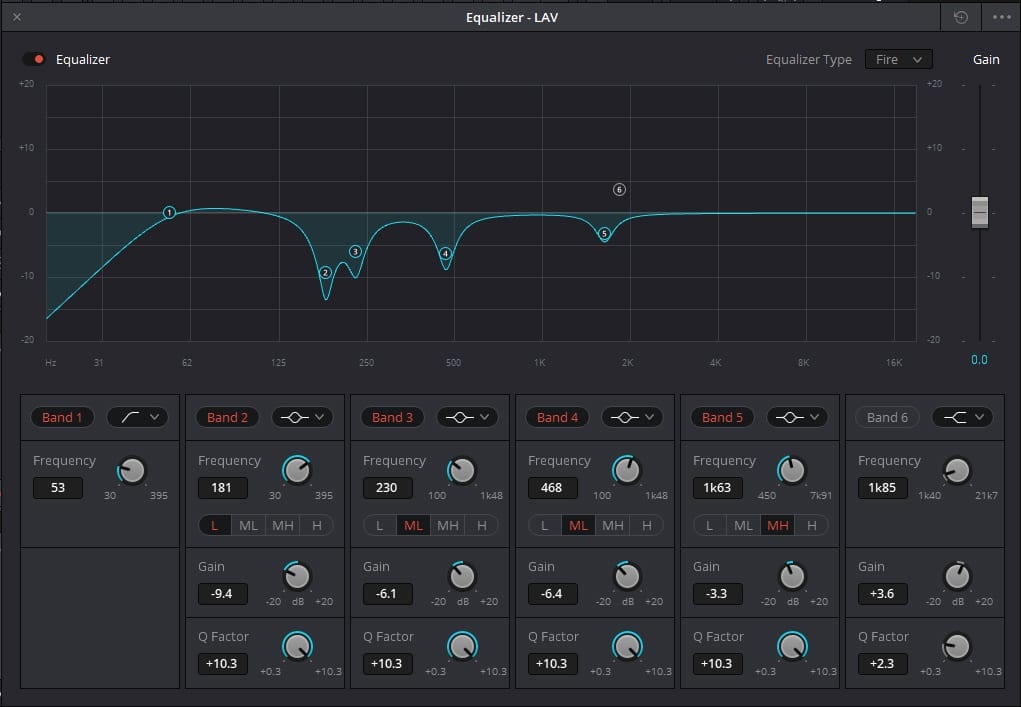
Dale’s vocal carve ended up looking a little something like this.
One final note on this subtractive EQ technique: When you start out in the low end of the human voice, try not to cut the fundamental frequency of your subjects voice. Thats where their voice starts, and where most of the power originates. These are usually anywhere from 85hz up to 200hz depending on gender/range/puberty. Cut that, and you cut their SOUL. (Not really, but maybe.)
Now remember when I was blabbering on about how microphones record a flat frequency response giving you an overall impression of the sound and more room to tweak, ala capturing raw/log footage? That’s why I usually add a bit of high end to these microphones to give the subject some presence and sparkle. I want to feel like I’m in the room with them when I’m watching these videos. So typically, I’ll implement some type of high-shelf on the final band, Band 6.
Select the band-shape that looks like a hand opening toward the right (highs) and boost it a few decibels. Scan the frequency left and right searching for that magic spot where the person’s voice comes alive and feels present. I generally will intentionally boost it too much to help hone in on where that presence is, and then bring it back down to a pleasing level once I’ve found it.

The High-shelf on Dale’s voice. Presence. Sparkle. Life.
Okay.
We’ve EQ’ed.
Honestly that’s the hardest and most time demanding step of voice sweetening, but by switching the EQ off and on you’ll notice a massive difference in clarity and presence. And like all good things that take time: It’s worth it.
The second step is a quick but crucial one : De-Essing.
Because we’ve boosted the top end of the voice with the high-shelf, we’ve also boosted the area where S’s live in speech. Way up there. A De-Esser is a plugin that only compresses a narrow bandwidth of EQ every time it occurs. So every time it hears an S, it quickly pulls down the volume of only that frequency area, and then brings it back up after the S is said.
Drag Fairlight’s De-Esser over to your Effects chain on your audio track and lets get started.

The stock De-Esser setting. Two knobs. You got this!
The Frequency knob lets you select where your esses are mainly living. By clicking on “Listen to Ess only” it temporarily cuts out anything not in that frequency range so you can really hone in on where that snakelike hiss is hiding.
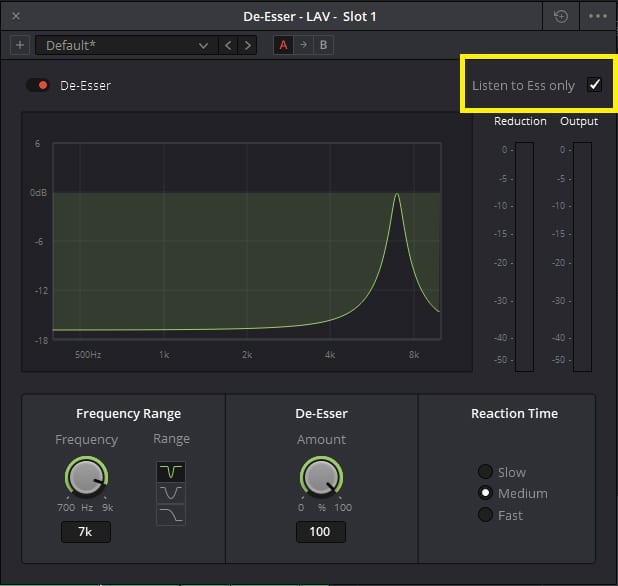
“Listen to Ess only” to fine tune your De-Esser. Not too long though; you’ll go mad.
Once you’ve found where the Esses are living, switch out of “Listen to Ess only” and dial in the amount of De-Essing with the..you guessed it: The Amount Knob. Careful here. Too much and you’ll start to give your subject a lisp and cut your highs. Play around with the “Reaction Time” settings to determine how much time for the De-Esser to kick in.
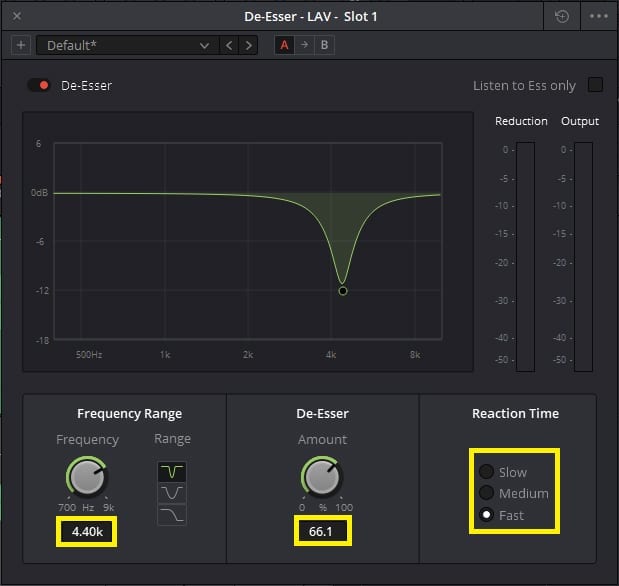
These settings worked for Dale’s voice.
Alright, we’ve de-essed. No more painful brightness every time someone says “She soley shoots cinema on Sony’s Cyber-Shot.”
Our final step in Voice Sweetening is Compression. There are as many articles and lessons about compression as there are stars in the universe so I’m not gonna go too in depth on the various theories and applications about audio editing’s black hole. For now just know that compression lowers the volume of louder bits to make everything more even.
Now the reason we compress after de-essing is because we don’t want our compressor reacting to those harsh S sounds that poke through after we’ve brightened the voice. We want it reacting to the overall volume of the voice.
Double click on the Dynamics box on the audio track to open Fairlight’s built in compressor.

Clicking on Compressor activates it.
Threshold determines at what level compression kicks in. Ratio determines how much gain reduction is applied. Threshold does nothing on it’s own, it merely indicates when that ratio of gain reduction should start, well, reducing. Attack allows you to have a slight delay before the compression kicks in, allowing for some of the initial signal to slip through. Release is the opposite; How long will the compressor act on the signal (that’s above the threshold) before it shuts off again.
Have I lost you?…I’ve lost you.
It’s important to remember that audio editing is best performed with your ears, and not your eyes. So don’t worry about numbers too much. Trust your ears above all else.
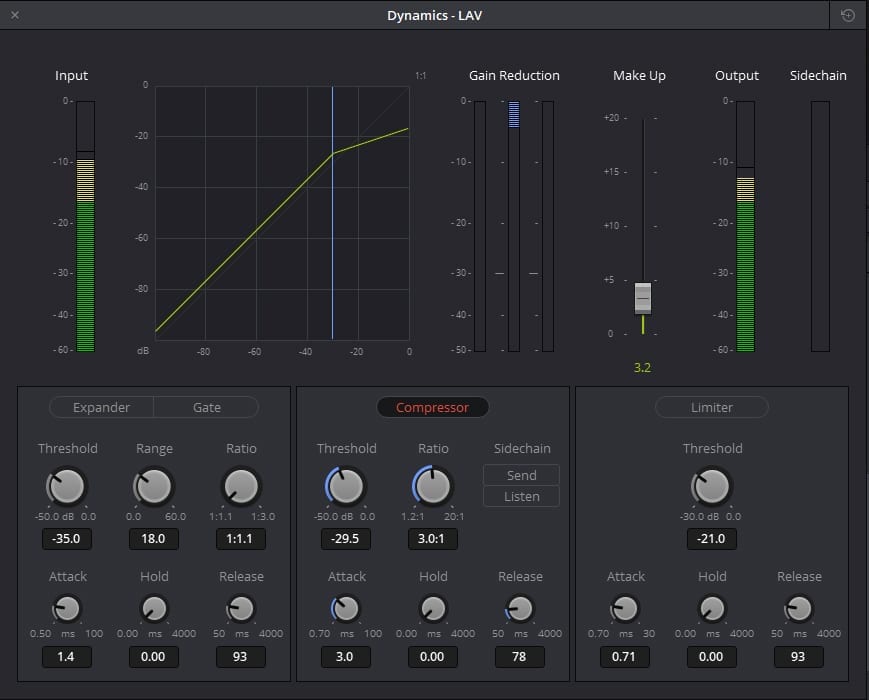
In the case of Dale’s voice, I wanted all signals above -29.5 (the threshold) to be compressed by a Ratio of 3:1. I set a quick Attack time of 3 milliseconds and a fairly quick Release time as well at 78 milliseconds. That worked for this audio track.
Every. Audio. Track. Is. Different.
Lastly, because we’re using compression to lower the dynamics of Dale’s speaking voice, which is dropping the volume of the louder bits, we’re then going to raise the overall volume of the track with the Make Up slider. When doing this, I find it helpful to switch the compressor on and off to better match the affected signal’s volume to that of the original; before we started compressing.

The Make Up slider helps with volume loss from compression. It won’t help your failing marriage. Or will it?
Phew! We did it. See, that wasn’t so bad was it? I promise you’ve spent much longer comparing camera sensors, LED lights, and sandbags than you’ll spend vastly improving your dialog tracks with these three steps.
EQ.
De-Ess.
Compress.
Trust me, Chris Nolan does it.

Hmm, maybe not.








Trackbacks & Pingbacks
[…] mentioned in my Voice Sweetening tutorial that we used compression to make our dialog track more even and consistent across the board. We […]
Comments are closed.